北海道電子機器|ソフトウェア開発、組み込み系システム開発-基本設計から量産までワンストップで対応します
北海道電子機器|ソフトウェア開発、組み込み系システム開発-基本設計から量産までワンストップで対応します







![]()
本連載の「第1回」は2018年11月でした。まさに光陰矢の如しです...。
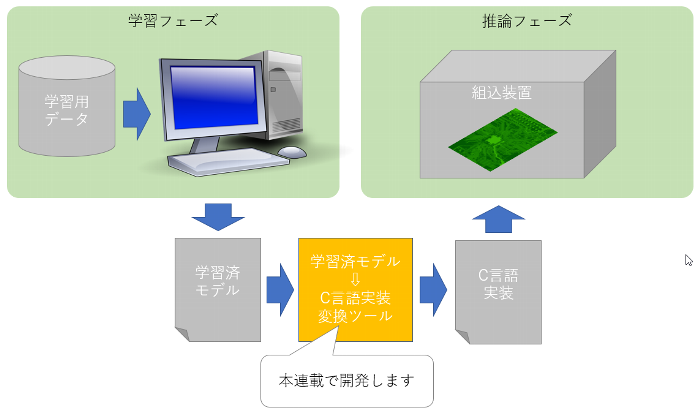
本連載では、以下のようなツール(図中の橙色部分)の完成を目標にしたのでした。
第1回は事前調査でしたが、その後状況が変化しているので再実施しました。
第1回の時点(2018年11月)ではTensorFlowが一番人気でした。
現在(2019年11月)の状況をあらためて調査した結果、「この記事」によれば、
TensorFlowとPyTorchの2強が突出しており、PyTorchが優勢になりつつあるようです。
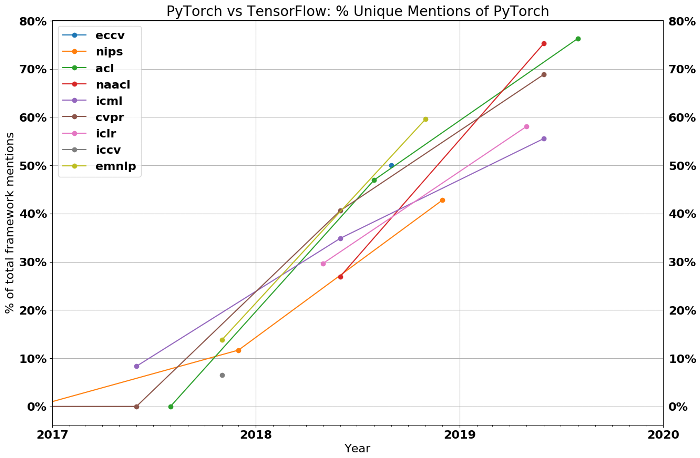
(図は「The State of Machine Learning Frameworks in 2019」より引用)
図中の各系列(eccv、nipsなど)は、主要なAI系学会の名称です。
縦軸は、TensorFlow/PyTorchのいずれかを使った論文の数に対する、PyTorchを使った論文の数の割合です。
ただし、TensorFlow/PyTorch両方とも使った論文と、Google/Facebook関係者の論文は除外されています。
この割合が50%を下回ればTensorFlow優勢、50%を上回ればPyTorch優勢と判断できます。
2019年を境に(研究の領域は)PyTorchが優勢になったことが見て取れます。
記事では「応用の領域は依然としてTensorFlow優勢だが、その状況も長く続かないだろう」と推測されています。
第1回の時点(2018年11月)では「ONNX」が優勢でした。
現在もこの状況に変化はありません。
第1回の時点では知識不足で知りませんでしたが、「深層学習コンパイラ」と呼ばれるものがあります。
簡単に言えば、学習済モデルをハードウェアで実行できる形式に変換するもので、
本連載の目標と非常に近い関係にあります。
最近では、OSなしの小規模な組込装置に対応できそうなものも出てきています。
当初は深層学習コンパイラに相当する部分を自作する想定でしたが、以下の理由により既存のものから選定して利用する作戦に変更します。
連載の再開にあたって調査した結果を踏まえて、以下のように方向修正します。
第1回の振り返りが長くなってしまいました。
以降から第2回の本題に入ります。
深層学習コンパイラ(Deep Learning Compiler)とは、簡単に言えば、学習済モデルをハードウェアで実行できる形式に変換するものです。
「この資料」がとても参考になりました。
資料のp11の一覧に記載されている深層学習コンパイラの中から、ONNXに対応しているものに候補を絞り、
人気度(GitHubのStar数)とOSなし小規模組込の対応状況を調査した結果を以下に示します。
| 名称 | GitHubのStar数(※1) | OSなし小規模組込の対応状況 |
|---|---|---|
| ONNC | 270 | -(※3) |
| TVM | 4,514 | μTVM(※4) |
| Glow | 1,777 | -(※3) |
| XLA | 137k(※2) | TensorFlow Lite for Microcontrollers |
| nGraph | 1,104 | -(※3) |
※1 GitHubのStar数は、2019年10月29日の値。
※2 XLAはTensorFlowのリポジトリに含まれるためXLA単独のStar数ではない。TensorFlowのStar数。
※3 これらは、現時点でOSなし小規模組込の対応が困難と判断した。
※4 μTVMは、現在開発中の模様。
調査結果を踏まえて、以下の理由によりTVMを選定しました。
次回は、【第3回】深層学習コンパイラのバックエンド対応を予定しています。
不定期連載ですので、いつになるかは不明です。まさか、また1年後になるのでしょうか?
(いやいや、それは許されないでしょう...!)
Written by 澤田

Copyright © Hokkaido Electronics Corporation.
 弊社社員が執筆するブログです。
弊社社員が執筆するブログです。 北海道電子機器公式YouTubeチャンネル
北海道電子機器公式YouTubeチャンネル 北海道電子機器の採用情報はこちらへ。
北海道電子機器の採用情報はこちらへ。